| Version 18 (modified by jaho, 14 years ago) (diff) |
|---|
LAG Developers FAQ
1. General
1.1 What is LAG?
1.2 What are the main components of LAG?
1.3 Why is LAG's code so messy?
1.4 How can I make LAG's code better?
1.5 Where can I learn some good C++?
1.6 Who can I ask for help?
2. Laslib
2.1 What is laslib?
2.2 What are LAS files?
2.3 What's the deal with LAS 1.3 files?
2.4 What do I need to know about laslib?
2.5 How do I make laslib a shared library?
3. Quadtree
3.1 How does Quadtree work?
3.2 How is Quadtree structured?
3.3 What is the reason behind subbuckets?
3.4 How does caching work?
3.5 What is the reason behind data compression?
3.6 What are LasSaver and LasLoader classes in the quadtree?
4. LAG
4.1 How is LAG's code structured?
4.2 How do I edit the GUI?
4.3 How does loading of files work?
4.4 How does saving of files work?
4.5 How is LAS 1.3 point format handled?
4.6 How is threading done?
4.7 How does rendering work?
5. Further Development
5.1 What are main ideas for further LAG development?
5.2 What are the major issues with LAG that need fixing?
5.3 What is lag memory issue?
5.4 Which parts of LAG's code need improvement?
5.5 What are some additional features that can be added to LAG?
5.6 What tools are there to help me with LAG development?
5.7 How do I use profiling tools to optimise my code?
1. General
1.1 What is LAG?
LAG stands for LiDAR Analysis GUI. It is a software which provides graphical user interface for processing and visualisation of LiDAR point clouds. LAG is written in C++ and uses Gtk (gtkmm) for its GUI, and OpenGL for rendering.
1.2 What are the main components of LAG
LAG consist of the main GUI application and the Lidar Quadtree library used for storing and manipulating the data. It also uses laslib library for handling LAS files.
1.3 Why is LAG's code so messy?
The lag has been in development since 2009 and there were at least four different people working on it, each with different coding style, ideas and barely any supervision. It is now much better then it used to be, but it's easy to see that different parts have been written by different people. Some parts of the code contain temporary solutions which were never implemented properly, since they worked at the time. Just because they work though, doesn't mean they are good solutions in terms of efficiency, maintainability etc. There is still a lot of room for improvement.
1.4 How can I make LAG's code better?
Take users of your classes into consideration and try to design easy to use and logical interfaces. Do some refactoring if you think it's going to make things easier to maintain, and to understand the code better. Use consistent coding style and comments. Use white space and indentation for readability.
Try to learn good coding practices before you start writing the code. It is better to spend some time planning and then writing an implementation, then writing a code that just works and then trying to fix it. For example implementing things like const correctness or exception handling from the start is much easier then adding it once everything has been written.
Profile your code instead of relying on your intuition of what "should be" faster. Use OO principles for the benefit of more robust code (eg. use polymorphism instead of huge blocks of if statements). Use common sense.
1.5 Where can I learn some good C++?
Whether you already know C++, come from C or are just starting to learn, it is a good idea to familiarise yourself with good programming practices before writing production code. Assuming you already know the basics of the language I highly recommend these two sources:
C++ FAQ - every C++ programmer should read. It's well written, to the point and covers a lot of things from OO design to freestore management.
Google C++ Style Guide - you don't have to blindly follow it, but it should give you an idea of what a good coding style looks like.
1.6 Who can I ask for help?
One problem with LAG is that it has been entirely developed by students, so the only people that know how it really works are most likely gone (thus this FAQ). For general help with programming you should probably ask Mike Grant or Mark Warren as they seem to know a thing or two about it. They also tend to be quite busy though so if you don't feel like bugging them Stack Overflow is always a good place to look for help.
2. Laslib
2.1 What is Laslib
Laslib is a library for handling various LiDAR file formats including LAS. LAG makes use of laslib for loading and saving points.
2.2 What are LAS files?
LAS is a binary, public file format designed to hold LiDAR points data. One alternative to LAS are ASCII files (.csv or .txt), which are however less efficient in terms of both processing time and file size.
LAS files consist of several parts: Public Header Block containing meta-data about the records (like min and max x, y, z values, number of points etc.), Variable Length Records with additional meta-data (like projection information), Point Records and in format 1.3 and later Waveform Records.
One thing to note about LAS is that point coordinates are stored as scaled integers and are then unscaled upon loading to double values with the use of scale factors and offsets stored in the header.
A detailed LAS format specification can be found at:
http://www.asprs.org/Committee-General/LASer-LAS-File-Format-Exchange-Activities.html
2.3 What's the deal with LAS 1.3 files
In addition to discrete point records LAS 1.3 files also hold full waveform data which is quite huge in volume. The point records have also been modified to include a number of new attributes related to waveform data.
New point format causes a problem to the quadtree library because point objects are much bigger in size thus affecting the performance and memory consumption. We don't currently have tools to process full waveform data, however we do sometimes include it in deliveries so we need some way of handling it.
2.4 What do I need to know about laslib?
There is no official documentation for laslib API, however it is a fairly well written C++ which provides an easy to use interface. The best way to learn laslib is to study the source code of programs included in lastools. It is quite powerful and even provides its own tools for spatial indexing (totally undocumented though).
The main classes of our interest are LASreader and LASwriter. A simple program that reads points from a file, filters out points with classification 7 (noise), prints points' coordinates and then saves them to another file may look like this (note there's no error checking or exception handling for simplicity, but you should always include it the real code):
#include <iostream>
#include "laslib/lasreader.hpp"
#include "laslib/laswriter.hpp"
#include "laslib/lasdefinitions.hpp"
int main(int argc, char** argv)
{
// Assume that's correct for simplicity
std::string filename = argv[1];
std::string file_out = argv[2];
LASreadOpener lasreadopener;
LASwriteOpener laswriteopener;
lasreadopener.set_file_name(filename.c_str());
laswriteopener.set_file_name(file_out.c_str());
// Filter out points with classification 7
std::vecor<char*> filter_args; // this simulates a command line arguments for parse() function further down
filter_args.push_back("filter"); // a dummy first argument
filter_args.push_back("-drop_classification");
filter_args.push_back("7");
filter_args.push_back(0); // null termination
lasreadopener.parse(args.size(), &args[0]); // &args[0] = *args so we're passing char** args instead of a vector<char*>
// Declare lasreader
LASreader* lasreader;
// Open the file
lasreader = lasreadopener.open();
// Create and open the writer
LASwriter* laswriter = laswriteopener.open(&lasreader->header);
// Loop through the points (note they will already be filtered)
while (lasreader->read_point())
{
// Show coordinates
std::cout << lasreader->point.get_x() << ", " << lareader->point.get_y() << ", " << lasreader->point.get_z() << std::endl;
// Write point
laswriter->write_point(&lasreader->point);
// Add it to the inventory (keeps track of min/max values for the header)
laswriter->update_inventory(&lasreader->point);
}
laswriter->update_header(&lasreader->header, TRUE);
laswriter->close();
lasreader->close();
delete laswriter();
delete lasreader();
}
2.5 How do I make laslib a shared library?
It seems that laslib is mainly developed for Windows users so there are no targets for shared libraries in the Makefiles by default. At the same time shared libraries are needed by LAG to work correctly. To fix this you're going to need to modify the Makefiles and add -fPIC option to the compiler. You'll also have to change the name of the library from laslib to liblaslib for the linker to detect it.
You'll normally find modified Makefiles somewhere around, so you can copy them after downloading a new version of laslib and hopefully they will work. If this is not the case, below is the part that needs to be added to the Makefile inside laslib/src folder.
all: static shared
# these targets set the output directory for the object
# files and then call make again with the appropriate library targets.
# This is done so that the fpic flag is set correctly for the library
# we're building.
static:
test -d static || mkdir static
$(MAKE) liblaslib.a OBJDIR=static
shared:
test -d shared || mkdir shared
$(MAKE) liblaslib.so.${VERSION} OBJDIR=shared EXTRA_COPTS=-fPIC
liblaslib.a: ${TARGET_OBJS}
$(AR) $@ ${TARGET_OBJS}
cp -p $@ ../lib
liblaslib.so.${VERSION}: ${TARGET_OBJS}
${COMPILER} -shared -Wl,-soname,liblaslib.so.1 -o \
liblaslib.so.${VERSION} ${TARGET_OBJS}
cp -p $@ ../lib
${TARGET_OBJS}: ${OBJDIR}/%.o: %.cpp
${COMPILER} ${BITS} -c ${COPTS} ${EXTRA_COPTS} ${INCLUDE} $< -o $@
You're not likely to have to alter this part and if a newly downloaded version of laslib fails to build with modified Makefiles, the first thing to check is if OBJ_LAS (the list of object files) hasn't changed since the previous release.
3. Lidar Quadtreee
3.1 How does Quadtree work?
The Lidar Quadtree library provides a quadtree data structure for storing and indexing points. It also contains a caching mechanism for loading and unloading points from memory.
Each node of the quadtree represents a bounding box in x and y coordinates. Whenever a point is inserted into the quadtree it is determined which of the four nodes it falls into and then the same happens for each node recursively until a leaf node is found. Whenever the number of points in a node goes above the maximum capacity specified on creation of the quadtree, the node splits into four.
When retrieving points a bounding box is passed to the quadtree and all nodes which intersect with it are queried for the points. It's quite simple really.
3.2 How is quadtree's code structured?
Quadtree.cpp
Provides an interface for the quadtree. It is the only class that should be used from the outside. It also holds metadata about the quadtree and a pointer to the root node.
QuadtreeNode.cpp
Represents a single quadtree node. Provides methods for inserting and retrieving the points.
Point.cpp
Represents a single point in space with three coordinates: x, y, z.
LidarPoint.cpp
Represents a lidar point with coordinates (inherits from Point) and other attributes like time, intensity, classification etc. Note that size of the point directly affects the size and performance of the quadtree, thus only necessary attributes are held inside this class.
PointBucket.cpp
A flat data structure which actually holds the points. Each quadtree node holds a pointer to a PointBucket which holds the points in an array of LidarPoint objects. The PointBucket is also responsible for caching and uncaching of data.
PointData.cpp
A struct to hold LAS 1.3+ point attributes which are stored separately, outside the quadtree.
CacheMinder.cpp
A class to keep track of how many points are currently loaded into memory.
3.3 What is the reason behind subbuckets?
The PointBucket class may hold copies of the same point in several arrays called sub-buckets. There are two parameters which control of how many sub-buckets are created: Resolution Depth and Resolution Base. The Resolution Depth determines the number of sub-buckets for each bucket and Resolution Base determines the number of points at each level by specifying the interval between included points based on a formula of Resolution Base(Level - 1). For example the default LAG values of 5 and 4 create 4 sub-buckets per bucket: one containing every point (50), second containing every 5th point (51), third containing every 25th point (52) and fourth with every 125th point (53).
The reason for this is rendering of points. For example when viewing a whole flightline in the overview window there is no need to render every single point or store all the points in memory at once. Thus sub-buckets containing every n-th point are used instead. Note that you could just pass every-nth point for rendering, but it is really the memory usage and caching issue that sub-buckets solve.
Because each resolution level effectively slowers the quadtree (some points need to be inserted n times into n arrays) for applications other then LAG, which make no use of sub-buckets, Resolution Depth and Resolution Base should be set to 1.
3.4 How does caching work?
Upon creation of the quadtree the user specifies a maximum number of points to be held in memory. Whenever a new bucket is created inside PointBucket::cache() the CacheMinder::updateCache(int requestSize, PointBucket* pointBucket, bool force) method is called with requestSize parameter equal to the number of points that will be held in that bucket. This number is then added to the value of CacheMinder::cacheUsed variable and compared to CacheMinder::totalCache, which is equal to maximum number of points that can be held in memory. If the sum of the to is smaller then maxim cache size the cachUsed variable is updated and a pointer to the bucket is added to the queue (std::deque) of cached buckets. If total amount of cache requested is greater then allowed maximum the buckets are taken from the front of the queue and uncached until there's enough space for the new bucket. (A note here: the force variable in updateCache() method is actually obsolete as it's always set to true).
When a bucket needs to be uncached, because there is no more room for new buckets in memory, PointBucket::uncache() method is called which serializes the bucket by compressing it and writes it to a file. Two lso compression is used for this together with two static variables to reduce the memory overhead. The serialization code looks like this:
// static shared working memory
unsigned char *PointBucket::workingMemory = (unsigned char*) malloc(LZO1B_MEM_COMPRESS);
unsigned char *PointBucket::compressedData = (unsigned char*) malloc(ceil(sizeof(LidarPoint) * capacity_ * 1.08));
// then inside PointBucket::uncache()
lzo_init();
lzo1b_2_compress((const unsigned char*) points_[k], sizeof (LidarPoint) * numberOfPoints_[k],
compressedData, &compressedDataSize_[k], workingMemory);
fwrite(compressedData, 1, compressedDataSize_[k], file);
fclose(file);
Once the data has been written, the bucket is deleted from memory and CacheMinder::update_cache() method gets called with negative requestSize to update the amount of used cache.
If a setPoint() or getPoint() method is called on an uncached bucked it is simply re-created from the file and CacheMinder::updateCache() is called to reflect this change.
3.5 What is the reason behind data compression?
To make caching faster.
PointBucket uses lzo compression to compress buckets before writing them to disk. It may seem like a sub-optimal solution but, since quadtree's performance is mainly IO bound, the compression time is still much lower then reading/writing to the hard drive. Since the volume of data gets smaller thanks to compression in the end it speeds up IO operations which are the major bottleneck.
3.6 What are LasSaver and LasLoader classes in the quadtree?
These should be removed at some point together with geoprojectionconverter. They are currently there only for backwards compatibility with other programs that use the quadtree (classify_las).
From design point of view these classes should not be a part of the quadtree which should only serve as a data container. In practice, when these classes were used, making any changes in LAG regarding saving or loading files required alterations to the quadtree which was less then convenient. Now that loading and saving has been moved to separate classes inside LAG it is much more maintainable. Additionally it allows individual point inspection during loading and saving, which was not possiblebe before.
4. LAG
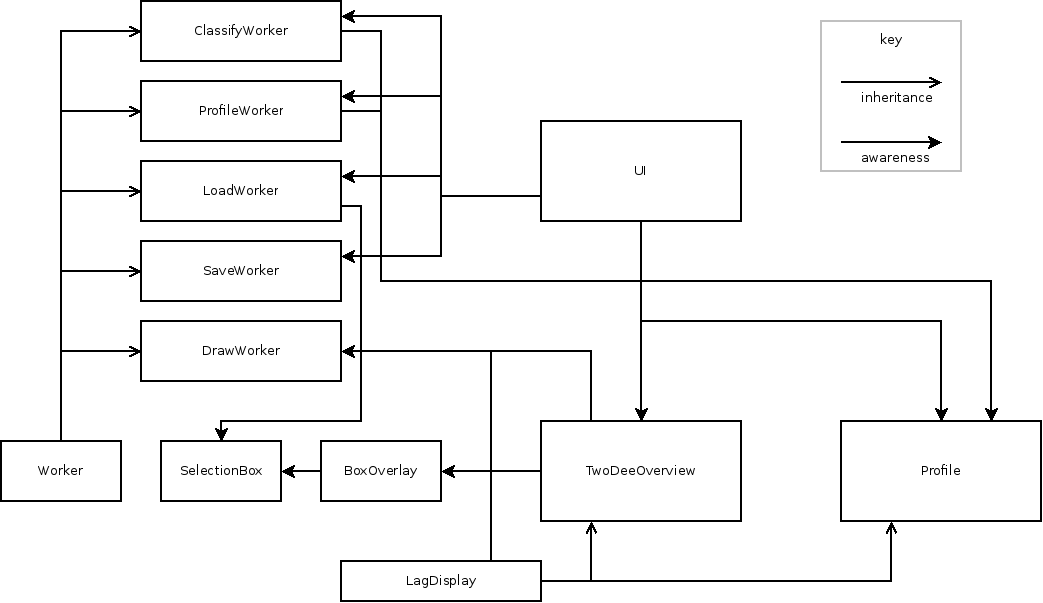
4.1 How is LAG's code structured?
lag.cpp
That's were main() function is. Not much happens here. The program looks for glade ui files, instantiates main classes, then starts Gtk thread where everything runs.
BoxOverlay.cpp
This is the box (fence or a profile) that you can draw on the screen.
ClassifyWorker.cpp
A worker class responsible for classifying points. This is kind of a stub at the moment, since the methods that do points classification are actually elsewhere and are only called from this class in separate thread.
Coulour.cpp
Represents an RGB colour.
FileUtils.cpp
An utility class which holds several methods used by classes that deal with files.
LagDisplay.cpp
An abstract class responsible for rendering. Profile and TwoDeeOverview inherit from this class.
LoadWorker.cpp
A worker class responsible for loading files. This is also the point where the quadtree is being created.
MathFuncs.cpp
An utility class with some common math functions.
PointFilter.h
A struct to hold a filter string which is then passed to the laslib::LASreadOpener.parse() method to create a filter for the points.
Profile.cpp
Represents the profile view of the data. The rendering of the profile and classification of points is done here in a particularly messy way.
ProfileWorker.cpp
A worker class that loads points selected in the overview into a profile. This is another stub as the actual methods for loading the profile are currently in Profile.cpp.
SaveWorker.cpp
A worker class responsible for saving points to a file.
SelectionBox.cpp
Holds the coordinates of a selection made on the screen.
TwoDeeOverview.cpp
A mess. Represents the 2d overview of the data and handles its rendering.
Worker.h
An abstract worker class.
UI classes
These classes represent top-level interface elements (windows and dialogs) and are responsible for connecting the UI to signal handlers.
4.2 How do I edit the GUI?
The GUI layout is stored in lag.ui Glade file which is in plain xml. This allows editing the interface without the need for recompiling the source code every time a change is made. The lag.ui file can be opened in Glade User Interface Designer which can by run with glade-3 command.
The interface of the application is created from xml using Gtk::Builder object, which is instantiated in lag.cpp and then passed by Glib::RefPtr to each of the classes that handle the GUI. All of these classes are located under src/ui folder and each of them has two common methods: void load_xml(builder) and void connect_signals() which are called in their constructors.
The load_xml(const Glib::RefPtr<Gtk::Builder>& builder) method gets widgets from the builder file and assigns them to the class members (pointers to Gtk objects). Widgets instantiated by Gtk::Builder have to be deleted manually. In fact, according to documentation, this only applies to top-level widgets (windows and dialogs), but LAG's authors seem to prefer to delete every single one anyway.
The connect_signals() method is responsible for connecting various input signals to class methods. An example lifetime of a Gtk Widget then looks like this:
// Declare a pointer to the widget (as class member)
class MyClass {
Gtk::Button* my_button;
void on_my_button_clicked();
}
// Load the widget from xml (in MyClass::load_xml(const Glib::RefPtr<Gtk::Builder>& builder))
builder->get_widget("mybutton", my_button);
// Connect some method to it (in MyClass::connect_signals())
my_button->signal_clicked().connect(sigc::mem_fun(*this, &MyClass::on_my_button_clicked));
// Delete the widget (in the class destructor)
delete my_button;
Modifying the GUI is just as simple as adding new widgets to the Glade file and then handling them in the ui classes.
4.3 How does loading of files work?
Upon pressing Add or Refresh button an instance of LoadWorker is created in the FileOpener class with all the parameters from the file opening dialog (like filenames, ASCII parse string, filters etc) passed to its constructor. Then its run() method is called which actually does all the loading and then sends a signal back to the GUI thread through Glib::Dispatcher when the loading has finished.
Inside the run() method if the first file is being loaded a new quadtree object is created with its boundary equal to the values taken from the file's header. Every time a new file is loaded this boundary is adjusted to accommodate new points.
Once the quadtree has been set up a load_points() method is called which loads points from a file one by one and creates LidarPoint objects to insert them into the quadtree.
If the file is in latlong projection a GeoProjectionConverter (which comes from lastools) is used to first adjust scale factors and offsets in the header, and then transform point coordinates. The points stored inside the quadtree are always in UTM projection as it is much easier to handle (in latlong x, y are in degrees and z is in metres which causes some difficulties with rendering).
4.4 How does saving of files work?
Upon pressing Save button an instance of SaveWorker is created with all necessary parameters from the save dialog passed to its constructor. Then its run() method is called where the saving actually happens.
Inside run() method an array of LidarPoint objects is created and then a query is run on the entire quadtree to get all the buckets. It then iterates through each bucket and through each point and then inserts each point which belongs to a given flightline into an array. Once an array fills up the points are saved to a file and new points are added from the start of the array until everything has been saved.
If the output or the input file is in loatlong projecion two GeoProjectionConverter objects are used to get correct scale factor and offset values in the header and then convert points' coordinates. This is because the points inside the quadtree are in UTM projection and if the input file is in latlong then its scale factors and offsets need to be converted to UTM. At the same time if the output file is in latlong point coordinates need to be converted with a different transformation.
4.5 How is LAS 1.3 point format and waveform data handled?
The problem with points in LAS 1.3+ files is that they contain a number of additional attributes which are used to describe corresponding waveform data, but which are not needed by lag. These values are all 32 or 64 bit and adding them to the LidarPoint class would effectively double its size. In turn they would considerably slower the quadtree and make it occupy additional memory. Therefore all these attributes are stored in a temporary file on the hard drive and then retrieved when points are being saved with help of LidarPoint::dataindex variable. (If you have any doubts it is much faster add several double values to LidarPoint class and profile some quadtree operations. The performance impact is huge and maybe it would be a good idea at some point to try to store coordinates as scaled integers and have the Quadtree unscale them whenever they're requested. It would make get_x/y/z() operations a bit slower but the overall quadtree quite faster.)
The LoadWorker class containst the following two static members:
static std::tr1::unordered_map<uint8_t, std::string> point_data_paths; static std::vector<int> point_number;
When 1.3 or higher format is recognised LoadWorker::load_points_wf() method is used which creates LidarPoint objects to be inserted into the quadtree as well as PointData objects which hold the remaining attributes. A temporary file is created for each flightline and PointData objects are serially written to it. The point_data_paths is used to map a flightline number to a name of a temporary file where PointData objects are stored and point_number vector holds the number of points currently loaded per flightline. This number is also assigned to LidarPoint::data_index so the exact location of its data in the temporary file can be retrieved by using LidarPoint::data_index x sizeof(PointData). Note that the actual waveform data is not touched during the process.
When LAS 1.3 points are saved the location of temporary file is retrieved inside SaveWorker::save_points_wf() method from LoadWorker::point_data_paths.find(flightline_number). Then for each saved point it corresponding PointData is retrieved from the temporary file with something like this:
char* buffer = new char[sizeof(PointData)]; PointData* temp; int s = sizeof(PointData); fseek(datafile, points[k].getDataindex() * s, SEEK_SET); fread(buffer, s, 1, datafile); temp = (PointData*) buffer;
Because laslib library doesn't support storing waveform data in the same file as point records it automatically sets start_of_waveform_data_packet_record field in the header to 0. We need to manually change it to the correct value:
fseek(fileout, 227, SEEK_SET); fwrite(&reader->header.start_of_waveform_data_packet_record, sizeof(I64), 1, fileout);
Finally we copy over the waveform data manually and attach it to the end of the output file. Note that this requires for LAS 1.3 files to be saved to a separate file after modification. Unfortunately there is no way around this with how laslib library currently works.
4.6 How is threading done?
It uses Gtkmm threading system and implements worker classes which do the work in separate threads, without blocking the GUI. All worker classes inherit from Worker.h which is pretty simple. It provides a start() method which launches a new thread and a virtual run() method with code to be executed. It also has a Glib::Dispatcher object for inter-thread communication (works like signals).
class Worker
{
public:
Worker() : thread(0), stopped(false) {}
virtual ~Worker()
{
{
Glib::Mutex::Lock lock (mutex);
stopped = true;
}
if (thread)
thread->join();
}
void start()
{
thread = Glib::Thread::create(sigc::mem_fun(*this, &Worker::run), true);
}
Glib::Dispatcher sig_done;
protected:
virtual void run() = 0;
Glib::Thread* thread;
Glib::Mutex mutex;
bool stopped;
};
Each GUI class which uses threads has a Worker member initially set to null. Then once a function that starts the work is called the worker is created and started, and signal handlers are connected to handle the Dispatcher objects:
// Check if we don't already have a thread running if (worker != NULL) return; // Create a new worker worker = new Worker(...) // Start the worker worker->start() // Connect signals worker->sig_done().connect(sigc::mem_fun(*this, &GUIClass::on_worker_work_finished)); // Signal that the work is being don to the user by displaying a progress bar or a busy cursor
Once the worker has finished it emits sig_done() signal in its run() method notifying the caller class and on_worker_work_finished() method gets called. Most worker classes implement more signals to notify about different events (for example load progress to move the progress bar). The idea stays the same though.
Additionally in GUI classes Glib::Mutex objects are used at the beginning of each critical section to avoid race conditions. Using brackets around the section makes sure that the Mutex::Lock object gets automatically destroyed.
// some non critical code
{
Glib::Mutex::Lock lock (mutex) // mutex is a class member
// critical code
} // lock gets destroyed here
4.7 How does rendering work?
I'm not quite sure. It's a mess and it definitely needs some refactoring. It does work however so I haven't changed it, focusing on other things.
Once the files have been loaded, a pointer to the quadtree is passed to LagDisplay, TwoDeeOverview and Profile. First LagDisplay::prepare_image() method is called which sets up OpenGl and gets all the buckets from the quadtree with advSubset() method. Based on the ranges of z and intensity values it then sets up arrays for coloring and brightness of the points in LagDisplay::coloursandshades(). Then resetview() method is called which sets up orthographic projection and conversion of world coordinates to screen coordinates.
After that a drawviewable() method is called in TwoDeeOverview and/or Profile which checks what part of the data is currently being viewed on the screen and gets the relevant buckets from the quadtree. It also uses a good number of boolean variables which are changed all over the place to make things harder to understand.If you were wondering how NOT to do threading in C++, here's a great example. Eventually we create a new thread and call TwoDeeOverview::mainimage() method passing it the buckets we've got.
In mainimage() we call drawpointsfrombuckets() which prepares the points for being drawn. For each bucket from the quadtree it determines the resolution level needed (sub-bucket) based on the current zoom and viewing area. Then for each point in that bucket it creates vertices with attributes of the point to be drawn (location, color, brightness) and passes them to DrawGLToCard() method in the main thread which draws the contents of the vertices to the framebuffer. Finally FlushGLToScreen() method draws the contens of framebuffer to the screen.
Simple as that.
5. Further Development
5.1 What are main ideas for further LAG development?
There are few categories of things that need to be done:
- issues that need fixing
- code improvements
- additional features
5.2 What are the major issues with LAG that need fixing?
Luckily there's not so many any more, however the major one is the memory consumption. This is quite a difficult problem, but it should be looked at before lag can be released to the public.
Another one is handling of the LAS 1.3 files, which works, but can be improved (eg. saving to the same file). This may not be possible though as long as laslib just ignores full waveform data.
Also there is an issue with rendering/loading thread where forcing ON_EXPOSE event while loading a file at the same time may sometimes cause a segfault. For example moving some window on top of the TwoDeeOverview window while file is being loaded may cause this. This is most likely caused by both loading and rendering thread trying to access the quadtree at the same time and I believe sorting out the rendering thread should solve this problem.
5.3 What is lag memory issue?
It's an unknown source of high memory consumption of LAG. It looks like either a memory leak, memory fragmentation or both. The reason to suspect memory fragmentation is that the memory usage keeps growing to some point then stays constant. It's easy to see when loading the same file multiple times. Also when using a heap profiler it will show correct and constant memory usage and will not grow as high, possibly because of custom memory pool from the profiler.
Probably the best way to fix it would be to create a custom memory allocator which is an interesting project on its own.
5.4 Which parts of LAG's code need improvement?
The threading is not quite finished. While LoadWorker and SaveWorker have been fully implemented, the ProfileWorker and ClassifyWorker need some improvement (so the work is actually done inside these classes). To add to that a progress indication for classifying points and loading a profile could be added.
PointBucket and CacheMinder may use some work, possibly implementing a custom memory allocator for better memory management.
There's still plenty of refactoring to be done (possibly a good thing to start with to understand the code better). Particularly the rendering, which works, but is kind of scattered between different classes and methods and its threading which is just bad. Ideally there should be a separate Renderer/RenderingWorker class with all the code in one place.
Finally there is always some room for optimisations.
5.5 What are some additional features that can be added to LAG?
Here are some ideas:
- A 3D overview. Not so useful for processing, but pretty cool for visualisation and possibly attractive for other users outside ARSF (once LAG is released to the public).
- Additional Loading/Saving features. For example an option to use shape files to filter out points, ability to import/export different file formats, support for more projections etc. Also improved support for waveform data.
- Plugins or scripting support. Probably scripting would be easier to implement, for example using Boost::Python. The idea is to provide an interface for lag/quadtree to a scripting language like python so even users that don't know C++ could add their modifications. For example classify_las could then be made a script or tool inside lag.
- Further GUI improvements. Eg. progress bars for loading a profile and classifying points, tool tips and other user-friendly stuff.
- Waveform visualisation.
- Multi-platform support.
5.6 What tools are there to help me with LAG development?
I'd recommend the following:
Gdb - best debugging tool on Linux.
Valgrind - an excellent set of tools for profiling, optimisation, memory leak detection etc.
gperftools - a set of performance analysis tools from Google.
5.7 How do I use profiling tools to optimise my code?
Profiling is better then your intuition when it comes to optimising code and you should do it often. It lets you easily identify bottlenecks and see how your changes actually affect the performance. It also lets you pinpoint functions that cause high memory consumption and find possible memory leaks.
To be able to use all features of profiling tools you'll have to compile your code with -g and -pg flags. In case of lag and quadtree in means adding them to Makefile.am AM_CXXFLAGS. They should be removed before rolling out a new release though as they negatively affect both performance and size of the executables.
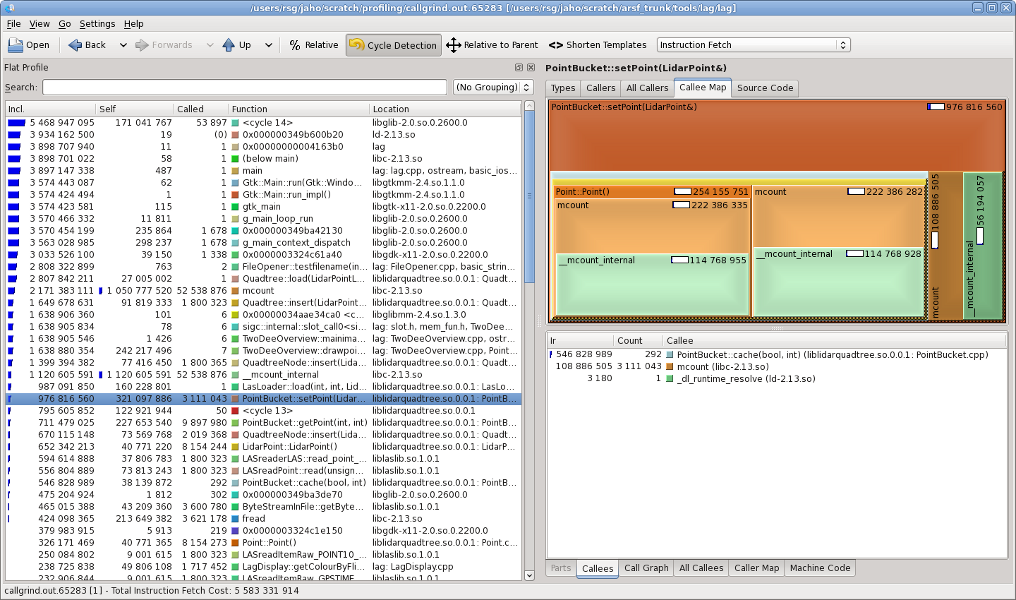
To get an idea about call times and frequencies of the functions you can use valgrind tool called callgrind. You run it like this:
valgrind --tool=callgrind lag
The lag will start as usual however it will run extremely slow. Run some operations (possibly such that you can repeat with no variations, like loading a single file) and close the program. The callgrind will have generated a call-graph file called callgrind.out.xxxxx which you can open in kcachegrind for visualisation.

Callgrind output visualised in kcachegrind.
From the output you will be able to see an inclusive and self cost of each function as well as go down into the hierarchy of its calees and their costs. To make the results comparable you should try to eliminate various external factors, like network lag, in between the runs, for example by placing the files you load on a local hard drive. Valgrind also offers a tool called massif for heap profiling which shows program's memory consumption. You run it in a similar way:
valgrind --tool=massif lag
To visualise the output you can use massif-visualiser.
Attachments (2)
-
kcachegrind.png
(361.5 KB) -
added by jaho 14 years ago.
kcachegrind
-
class_diagram.png
(17.2 KB) -
added by besm 12 years ago.
Class Diagram
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip