#115 closed bug (fixed)
ATM bands marked bad suspiciously
| Reported by: | benj | Owned by: | mggr |
|---|---|---|---|
| Priority: | immediate | Milestone: | |
| Component: | az* programs | Keywords: | |
| Cc: | mggr | Other processors: |
Description (last modified by benj)
Some ATM lines for IPY have bad bands marked for some lines. However, the bad parts seem to correlate with areas where there is bright sunshine shining on white snow - in other words where the value is going to be pretty close to max. It's possible either this is incorrectly causing it to be classified as bad, or else that the max value is itself being used to mark bad data.
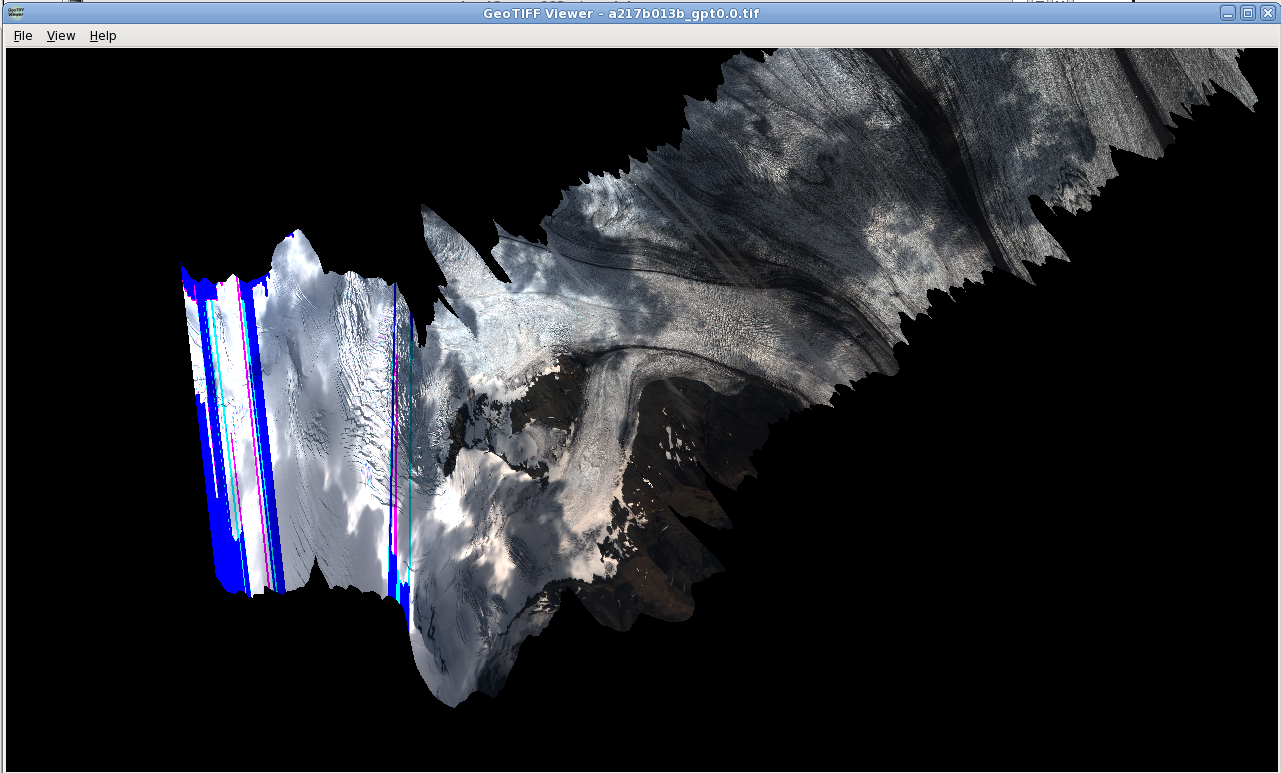
Eg. Green Box line 1:
")
Attachments (5)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (24)
Changed 18 years ago by benj
comment:1 Changed 18 years ago by benj
- Description modified (diff)
- Type changed from task to bug
comment:2 Changed 18 years ago by benj
Also occurs in flights where there is a significant amount of bright cloud. May be related to overflowing or sign handling issues - telling azatm to mark overflowed values as fffe rather than ffff has no visible effect on the level 1 (though oddly it seems to improve the level 3 tif a bit), but looking at the raw values suggests that the overflowed values may be over 32k. If the values were being checked for overflow as 16-bit unsigned (max value ~65k) but were elsewhere being used as 16-bit signed (max value ~32k) then when they went over 32k they would not be detected as overflowed pixels but would instead overflow and go negative, and when this was detected they would be set to zero (which is what is occurring).
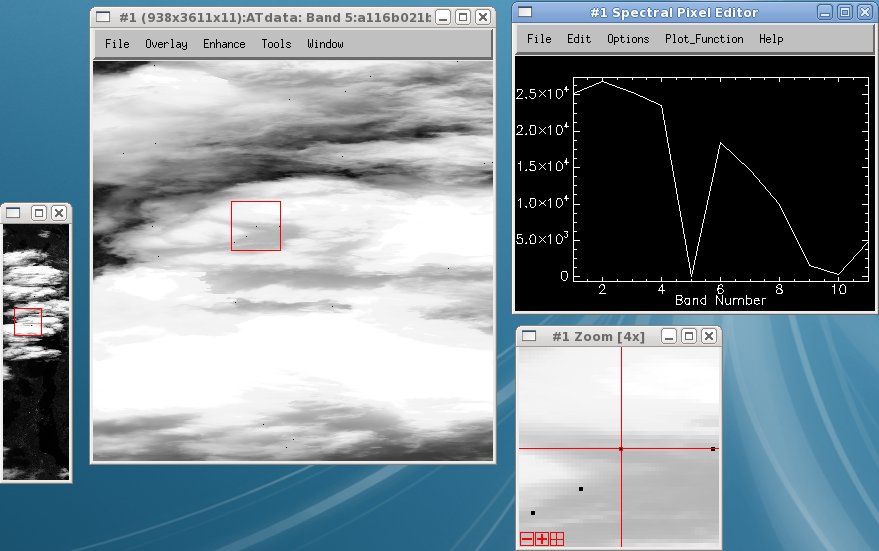
Windermere/Esthwaite day 116b ATM line 1, level 1 - note black inside of clouds:
comment:3 Changed 18 years ago by benj
Windermere/Esthwaite day 116b ATM line 1, level 1 - note black inside of clouds:

comment:4 Changed 18 years ago by benj
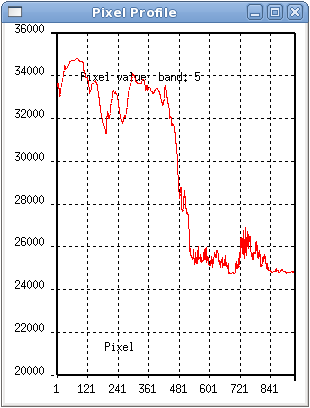
Band stats (below) from azatm for above flight line. Note absence of overflows but lots of underflows in affected bands. Suggests overflowed cloud pixels being incorrectly detected as underflows.
Band stats... band : 1 2 3 4 5 6 7 8 9 10 11 CALmin : 24517 24470 24420 24494 24512 24697 24663 24274 24360 24471 0 DNmin : 473 348 613 247 86 44 9 4 1 1 4346 DNmax : 47206 40056 25702 37684 21531 21992 12236 17824 5184 1085 12196 under : 4 3 131740 3 138780 62125 324828 3 669936 876935 601 over : 4 0 0 0 0 0 0 0 0 0 0
Also, pixel profile for cloud values - note sudden drop from >32k to <32k:
![]()
comment:5 Changed 18 years ago by benj
- Priority changed from medium to immediate
Decided to hold ATM data for now pending a fix to this - upgrading to immediate
comment:6 Changed 18 years ago by benj
Don't think the -cuo option in azatm is working (so can't test setting under/overflowed pixels to values other than default). Separate issue, raised ticket #121.
comment:7 Changed 18 years ago by benj
-cuo is actually working (see #121). If you set the underflow value to be 32767 (215-1), it stops the middle of the clouds being black and you get a sensible tif out of it (ie it doesn't mark the bands bad). Confusingly, if you set the underflow value to be 0xffff (corrected default for the overflow value), it stops the middle of the clouds being black in the hdf (it sets them all to 65k, even though the original value was 34-35k) but doesn't solve the original problem - it still marks the bands bad.
comment:8 Changed 18 years ago by mggr
Contacted Bill. Work order will be 200804-1.
comment:9 Changed 18 years ago by mggr
This turns out to be complicated, but amounts to the calibration multiplier causing the stored, calibrated data value exceeding the range of an unsigned int, thus overflowing. The best fix appears to be to alter the radiance scaling multiplier (always been 1000x so far) to allow us to rescale the calibration to fit.
Long email convos follow:
Mike, After our tcom this pm I had a word with Phil and, as I thought, the phenoemena of the ATM blackout, after calibration, in areas of bright scene is caused by the derived calibration values from the old ATM test bench are incorrect. So that this makes sense, the way the ATM system works from the photodiodes on is: the original ATM electronics drive the photodiodes so that a bright scene item is registered as a negative voltage and a dark item as a positive value. The AZ16 input amplifiers adjust this voltage range and the A2D digitise it giving the digital rage -32768 to + 32768 ; negative being bright and +ve being dark. To comply with convention of 0 being black and 64k being white, in qcdisplay and azatm, I convert the raw range with: DNconv = 32768 - DNraw So if you have very bright values they will be down to -32000 which converts to 64000 before calibration. Calibration applies an offset and scale, in theory, to allow for the full sensor range and convert it to the usual at sensor radiance units using the equ: DNradcal = ( DNconv - DNoffset ) * radcal_scale This radcal_scale also includes the scaling to get the resultant value within the 0-64k range of an unsigned integer. What is happening in your glacier and cloud scenes is: the bright values of, say -32000 convert to: 32768 - - 32000 = 64768 and with typical offset and scale values convert to: ( 64768 - 24000 ) * 2.0 =~ 80000 these exceed 64k and are set to zero. The solution is one or more of: 1. easiest: apply a scale factor to the calibration file scale values, so at least you can quickly see the detail in bright areas 2. ignore the real problem and store the result in a floating point value. 3. sort out why the calibration does not cater correctly for the full scene brightness range, particularly at the bright end. [this will including checking the calibration of the ATM test bench] I will let you have slightly modified qcdisplay which lets you list pixel profile raw values, ie prior to 0-64k conversion. I could mod azatm so that the radscale value is actually used, at present it is just assumed to be part of the calibration file values. Oh yes, you get various vivid colours because different band clap out at different pixels so some may be black giving reds, greens and blues form the other bands!! Perhaps Andrew could provide some words of wisdom? Br Bill
Reply:
Hi Bill,
Bill Mockridge wrote:
> What is happening in your glacier and cloud scenes is:
>
> the bright values of, say -32000 convert to: 32768 - - 32000 =
> 64768 and
>
> with typical offset and scale values convert to: ( 64768 - 24000 ) *
> 2.0 =~ 80000 these exceed 64k and are set to zero.
Ok, that makes sense and explains what's happening. To paraphrase, the
scale factor we've chosen is high enough that, at the brighter end,
we're getting values that are greater than 64k, exceeding the
representational range of an unsigned int as used in the HDFs.
A smidge of maths indicates the highest non-overflowing scale factor we
can have with a 24k dark value and light values going up to the full 64k
is around 1.57 (which is a little odd since our band 7 multiplier is
1.50, but perhaps the range is a little less than 65535).
[ comes from
DNradcal_max / (DNconv_maxish - DNoffset) = radcal_scale
e.g. 65534 / (64768 - 24000) = 1.6075
]
That also ties up with a valid dynamic range of 24k - 64k = 40k.
Spreading 40k numbers across 0 - 64k would give a multiplier of about
1.5.
> The solution is one or more of:
>
> 1. easiest: apply a scale factor to the calibration file scale
> values, so at least you can quickly see the detail in bright areas
This seems workable and relatively easy - if we set the calibration to
be, say, divided by 2 and set the radiance scaling factor to 2000 rather
than 1000, then it should all come out within the 64k range (or whatever
the suitable multipliers are).
On the downside, this won't be directly comparable (as in, viewing the
output lev1 DNs) with other sensors, which are radscale 1000. We may
also lose dynamic range..
Looking over the line I sent you, I see overflows in band 3 (cloud),
which has a calibration multiplier of 3, implying we should probably
divide it by 10 (and raise the radiance scaling factor to 10000 as the
nearest power of ten). That'd presumably also have nasty knock on
effects in that we'd be compressing the dynamic range in order to fit
the ultrabright whites and would lose some resolution at the lower
values?
To make this work, we need to be able to adjust the values in the
calibration file (easy) and to change the reported radiance scaling
factor in the HDF (presumably done already or easy?).
> 2. ignore the real problem and store the result in a floating point
> value.
Would this cause us to lose dynamic range? If it's a float32, we should
be able to represent any integer up to 2^24 without loss of precision.
The main costs would be disk space / CPU time and any implementation
fixes as it's not a tested route?
> 3. sort out why the calibration does not cater correctly for the full
> scene brightness range, particularly at the bright end. [this will
> including checking the calibration of the ATM test bench]
As I understand it (please feel free to correct me!), the problem is
that if the multiplier is greater than 1.5 or so as above, the output
will overflow at some valid/sensed-but-sub-max brightness. This
multiplier is the slope of the line between the dark value and the light
value.
I'm assuming the dark value is fixed (ie. the ATM returns the same
voltage in blackness) and that we can't cause that to change.
If the calibration of the bench is off, as is likely, the value of the
light point will move and may lower (or raise!) the slope, but it's
still entirely possible for it to be greater than 1.5 even if we have
the perfect calibrated value.
The only other control we have is the radiance scaling factor in the HDF
- that seems to be only way in which we can cause the multiplier to drop
below 1.5. As I understand it, this has historically been set to 1000
for ease of interpretation and because it fit the data ranges viewed.
This goes back to solution 1.
So, unless the light bench values are a long way off, we're unlikely to
drop the multipliers enough to contain the full valid ATM range. The
comparison against other sensors in the data quality report says we're
in the same ballpark, so the multiplier isn't far off either way.
Or I could be misunderstanding something.. it's been a long time since
the last coffee ;)
> Perhaps Andrew could provide some words of wisdom?
Yes please :) I guess one of the most main factors is going to be how
important these ultrabright whites are. If it's cloud, the IPY people
probably won't care (apart from getting scans blacked by it) - are they
likely to care about very bright snow? I'm told the cloud campaign in
Chile will focus on only Eagle and Hawk, so that shouldn't be a problem.
Cheers,
Mike.
P.S.
Incidentally, if you're curious about exactly how the calibration
numbers were computed, see:
http://www.npm.ac.uk/rsg/projects/arsf/trac/wiki/Processing/RadiometricCalibration/ATM
and
http://www.npm.ac.uk/rsg/projects/arsf/trac/browser/arsf-pml/trunk/radiometric_calibration/atm
(bug reports welcome!)
I also have a log of the calibration runs, so can provide dynamic
ranges, etc, and the values for the light bench that were used.
Supplementary:
Mike, One thing I forgot to mention in my original email was that the input circuits to the A2Ds are adjusted so that they cover more than the expected input voltage range from the photodiodes. So in theory one should never see anything like -32767 or +32768. In fact I think 0xefff and 0xffff are used as A2D flag values indicating over or underflow; I will try and locate a data sheet and check. Looking at the raw values for the clouds I can see a -32737 and several around -32740 and from the water: 32740s. I will check through qcdisplay and azatm to make sure all places that handle the raw values deal correctly with the full short range for stats etc. Don't forget that you can just do a run with no radcal if you want to at the cloud details - just leave off the cal file path. Br Bill
Supplementary reply:
Bill Mockridge wrote: > One thing I forgot to mention in my original email was that the input > circuits to the A2Ds are adjusted so that they cover more than the > expected input voltage range from the photodiodes. So in theory one > should never see anything like -32767 or +32768. In fact I think > 0xefff and 0xffff are used as A2D flag values indicating over or > underflow; I will try and locate a data sheet and check. Ok, that'd limit the range and probably explain why the multiplier of 1.50 still overflows :) > I will check through qcdisplay and azatm to make sure all places that > handle the raw values deal correctly with the full short range for > stats etc. Thanks, that'd be useful too :) > Don't forget that you can just do a run with no radcal if you want to > at the cloud details - just leave off the cal file path. I took a look at one of the affected IPY datasets (201, Russell Glacier) and it has the great majority of the scene affected, including most of the study box, so I guess we can't get away with it only affecting clouds :/ I also had a peek at azatm and don't see any options for storing as float rather than uint16, so I guess that'd need significant modifications to make that work and probably makes the #2 option impractical? That leaves us stuck with tinkering with the calibration scale factors - we'll have a play with those and see if it works. Cheers, Mike.
comment:10 Changed 18 years ago by mggr
Outcome:
- Bill will amend azatm to allow us to specify a radiance scaling factor (done) and apply this to the calibration file values. If we don't have this, we'll need to manually divide through the calibration files, which is likely to cause confusion due to many different-but-not-really cal files.
- Bill will correct the stats in azatm and the display in qcdisplay
Anticipating fix for 1 by the start of next week, and a day or two for 2.
comment:11 Changed 18 years ago by mggr
(communicated this is blocking ATM, so Bill will hurry on part 1)
comment:12 Changed 18 years ago by mggr
Bill supplied a fixed azatm - turned out to be an uint16 conversion error after all! All Russell Glacier (IPY 201/2007) works fine now, so considering this fixed.
comment:13 Changed 18 years ago by benj
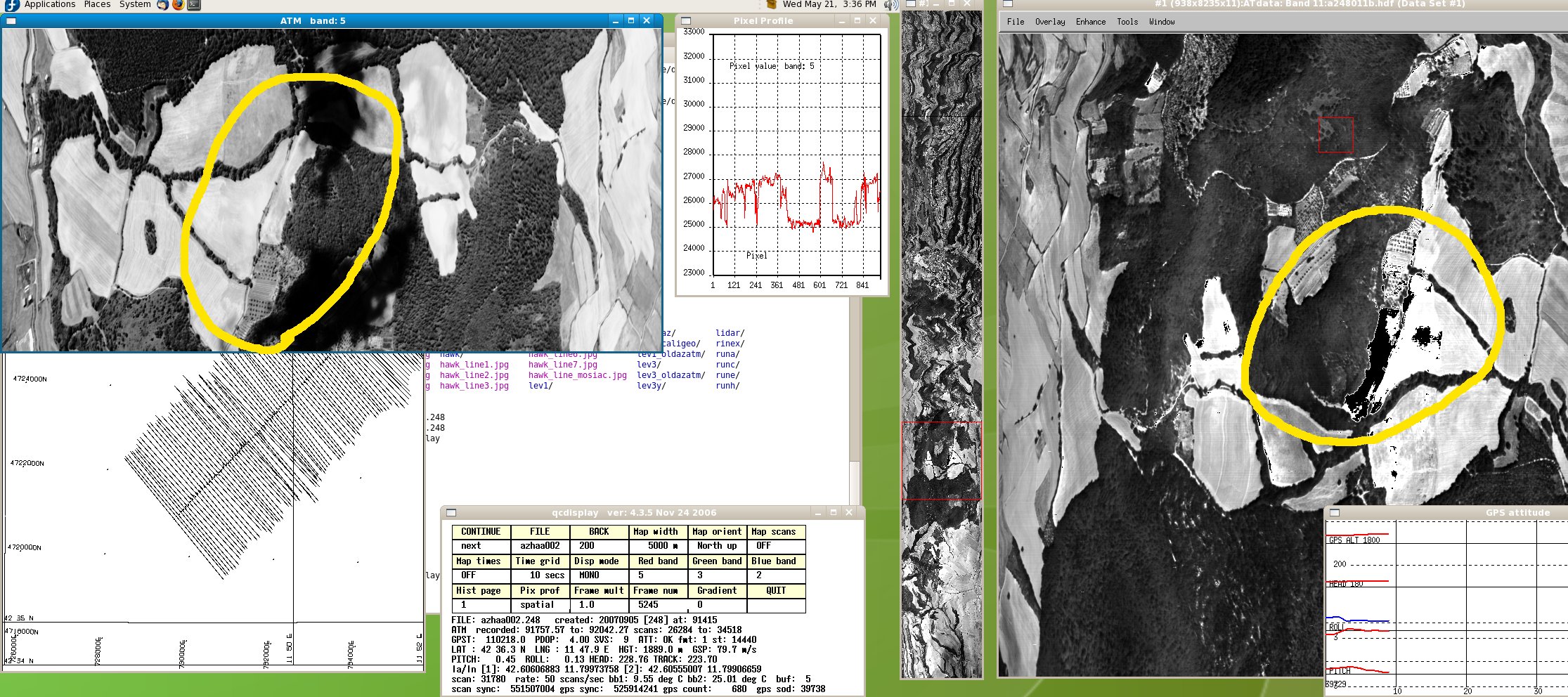
Mostly fixed (large black areas now gone), but still seems to have a few scattered black pixels in white(ish) areas in ATM bands 3-7. Oddly doesn't appear to be in max white areas but rather in slightly lower (greyish) areas. Black pixels in different places for different bands.
![]()
Changed 18 years ago by mggr
comment:14 Changed 18 years ago by mggr
- Owner changed from benj to mggr
- Status changed from new to assigned
Looks like band 11 is still suffering from the same issue. Contacting Bill to see if it's the same problem (band 11 is handled differently for calibration so he may not have hit that bit of code).

comment:15 Changed 18 years ago by mggr
Bill sent a new azatm (332), which has cured the band 11 issue. We're still seeing small isolated black pixels as in the image above (2 up). Mentioned this to Bill on the phone and he might take a peek. Doesn't look serious enough to prevent delivery imho.
comment:16 Changed 18 years ago by mggr
Work orders renumbered to make it obvious when one is missing. This work order is now wo2008002.
comment:17 Changed 18 years ago by mggr
Blackouts reappear when in bad scan correction mode. Reported to Bill 25/Jun, fixed same day (new azatm.333).
comment:18 Changed 18 years ago by mggr
- Resolution set to fixed
- Status changed from assigned to closed
comment:19 Changed 18 years ago by benj
Split off #189 to track issue with black flecks
ATM line 1, level 3 for Green Box (IPY)